Introduction
This page was started because I was updating one of my web pages that is practically nothing but links and found that nearly half of them were no longer valid.
It would be nice if people kept their web pages online forever, but that is never going to happen. Web pages, even entire websites, are ephemeral. Some have been, and will be, around for a long time. This one was started 20 years ago and will probably be going until I can no longer maintain it, but others come and go.
Link rot also known linkrot, dead link, or a broken link, are a nuisance and frustrating when you are following links from one website to another. Even worse, because it is fixable and shouldn't be happening, it happens when clicking links to a page on the same site. These broken links trigger a 404 not found error by the server and either a standard or customized error message is displayed:

Standard Apache web server 404 not found error message
Google's 404 not found error message

Microsoft's 404 not found error message
Wikipedia / Wikimedia 404 not found error message
My Internet Service Provider (ISP) was Time Warner Cable but now Spectrum. What they do if they do not recognize the top level domain (TLD) at all is provide a search page based on the URL they were given:
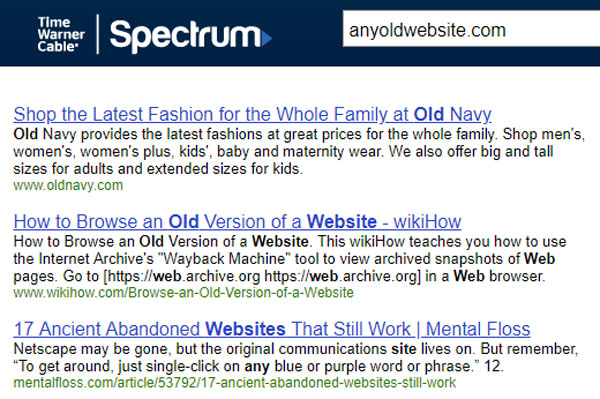
Spectrum 404 search page
Causes
There are numerous reasons a web page or resource might not be available. It might be the web editor on the linking site made a mistake in the Uniform Resource Locator (URL) they created. A page or document might have been renamed, moved or totally removed by a web editor. The entire website might have renamed, reorganized or simply deleted by a web editor. The result is going to be the same - the 404 not found error message of one sort or another is going to be displayed.
There are legitimate reasons why web content needs to be removed. There may be copyright or other legal issues with it, or it may be simply outdated - my own sites contains plenty of that.
I created my first web pages in 1999 and, apart from the look and feel of the site, I made what I now consider to be some serious mistakes in the design of it. Like many people at the time I made the some I used free web hosing from the likes of Lycos Tripod, FreeServe (disappeared just a year later in 2004), 250Free (was having problems since 2002 and disappeared completely in 2011). That wasn't so bad as in November 1999 I bought the domain name brisray.co.uk and pointed that to whatever free host I was using at the time. I moved to the US in 2001, and made the dreadful mistake of not renewing the domain name. A simple search of Google shows less than 30 pages pointing to the pages on my old brisray.co.uk domain but I feel I should have renewed and kept it. After I let it lapse someone else got it, but never did anything except park it, which means there's no useful content on it, but it can't be rebought, and I haven't been able to get it back.
Other people may start a website and get bored with it or for whatever reason let the domain name lapse.
Prevalence
Link rot has been recognized as a problem for over 20 years. Wikipedia quotes several studies that have variously found that "that about one link out of every 200 disappeared each week from the Internet," half a website's links are broken after 10 years with some sites reaching a 70% link failure rate in the same period, while other studies found some websites had a 50% link failure rate in just 3 years, websites have a 5% incidence of link rot per year, and that just 62% of the broken link targets were archived.
In 2003, Brewster Kahle who founded the Internet Archive, said in a Washington Post article that "The average lifespan of a web page today is 100 days." Two other pages, which themselves also suffer from linkrot, put the average lifespan at somewhere between just 44 and 75 days. These were articles written by Nicholas Taylor, Information Technology Specialist for the Repository Development Group (2011) and Marieke Guy, research officer in the Community and Outreach Team at the United Kingdom Office for Library and Information Networking.
The 44 day figure comes from Brewster Kahle in "Preserving the Internet" which appeared in Scientific American in 1997 and which itself is now only available in the Web Archive. The 75 day figure comes from the paper Persistence of Web References in Scientific Research by Steve Lawrence et al that appeared in a 2001 issue of IEEE Computer.
44, 75, 100 days, whichever is actually closest, the availability of a particular web page is a a lot shorter than I originally thought.
As a Visitor
Broken links on a website are a nuisance and annoying. This section of the page explains some methods of finding the page the link goes to.
All browsers allow you to view the source HTML of a web page and that includes all the links on it. You can usually do this by right-clicking on a page and choosing something like "View page source" or something similar. All will allow you to inspect a link on a web page by right-clicking on a link and choosing "Copy link address", "Copy shortcut" or something similar and the URL can then be pasted into Notepad or another editor for inspection. There are other methods and those are given on sites like Computer Hope. It may just be a spelling or syntax mistake on the part of the web editor and looking at the link may provide a clue on what it should be.
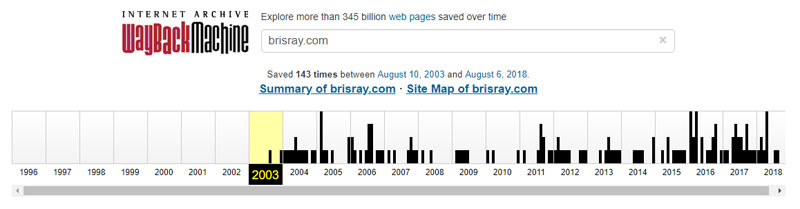
One of the easiest ways to retrieve a broken link is to use the Internet Archive Wayback Machine. Copy the URL into their search box and it will find any page it has indexed since 1996. The Internet Archive cannot archive every page of every website, some sites actively disallow their bot from archiving it and people may request their content be removed from the archive; but it still a very useful tool.
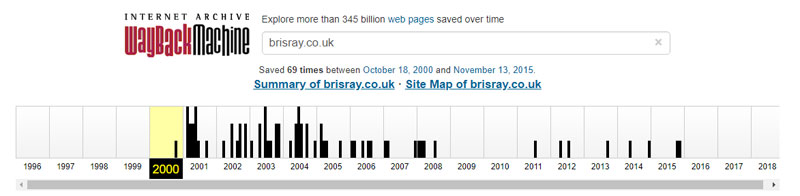
Internet Archive Wayback Machine captures of brisray.co.uk (above) and brisray.com (below)
There are two browser extensions available for the Internet Archive. One created by the Internet Archive itself and an unofficial one by verifiedjoseph. Both will allow you to submit any page to them for archival and to search the archive for previously archived pages. Also, in the official version, if a 404 not found error is encountered while browsing the web then a notice will appear asking you you want to view the archived version if it is available.
The official (above) and unofficial (below) Internet Archive web browser extension.
There are other web archives around such as Archive.is, Perma.cc and others but the Internet Archive Wayback Machine is the best known.
If a link to a web page is broken it might be possible to find it by copying the link to the browser address bar and going down the directory tree until there is some sort of clue where the page you want is. Suppose the link goes to website.com/this/that/other.htm and other.htm cannot be found. You could try removing that from the URL and going to website.com/this/that, if that fails go to website.com/this. It could be one of the menus in those main directories point to the page you are looking for.
As a Web Editor
Twenty years ago Tim Berners-Lee and Jakob Nielsen were both complaining about link rot and offering advice on how web editors could do to prevent it happening. Most of it comes down to planning the links in the first place and if they do have to change, then use redirects to point to the correct page.
Web content does become outdated, and on my sites, rather than destroy the page, I prefer to keep it but put warnings on it that the content may no longer be relevant or useful. A web editor may link to someone else's page that becomes obsolescent, when I do it, and can find it, then I'll keep the link on my page but add a note on my page explaining why the page is outdated.
When I rename or move pages I try to use some method, usually server 301 redirects, to point to the new name or location - see redirection.htm. External links on my pages are more of a problem, I have thousands of them.
You cannot just copy entire web pages and other documents just in case they disappear. There is (was?) a project that attempted to do that at least on WordPress and Drupal sites and that is Amber. Amber takes a snapshot of a linked page and if the original becomes unavailable will display the archived page instead.
For my external links I rely on the tools listed below to try and find them. Once a broken link is found, I'll search the various web archives for the pages. If I can find them then I will link to the archived pages. For example, the site about HMS Gambia was active from 2004 but disappeared in 2014. Now the only place the original site exists is in the Internet Archive Wayback Machine. If I cannot find the original pages, then I'll try and find one with similar content or delete the link altogether.
Tools
There are plenty of tools around to help find broken links on websites, many of them online and a few available as browser extensions. When using these tools, be careful of how deep you crawl other people's websites, I prefer just to check just the pages I link to rather than do any deep crawling of other websites. Be aware of how these utilities work. They respond to the server error code, 301/302 redirects, 400 resource not found, 500 server error codes etc., but the linked page may be completely different to the one originally linked to; the content may have changed from the time it was linked to. Unfortunately, most automatic tools can only tell you if the URL still exists, not what is on it!
The following list are ones that I use and found to be most useful:
Bing Webmaster Tools
Google Search Console
W3C Link Checker
Xenu Link Sleuth - An older utility but still great at what it does
Sources
A longitudinal study of Web pages continued: a consideration of document persistence by Wallace Koehler (2004)
Cool URIs don't change by Tim Berners-Lee (~2000)
Fighting Linkrot by Jakob Nielsen (1998)
Internet Archive Wayback Machine
On the Web, Research Work Proves Ephemeral by Rick Weiss (2003)
Persistence of Web References in Scientific Research by Steve Lawrence et al (2001)
Preservation of Web Resources: A JISC-funded Project by Marieke Guy (2009)
Preserving the Internet by Brewster Kahle (1997)
The Average Lifespan of a Webpage by Nicholas Taylor (2011)
Wikipedia: Link Rot
This page created December 24, 2018; last modified August 8, 2021