Introduction
The nice thing about Apache web server, whether on Windows or Linux is that it just works straight out of the box. There are times when the file has to be edited and this page documents some of the changes I have made to mine.
I use Fedora Linux and so my httpd configuration file is at /etc/httpd/conf/httpd.conf but the file may be named something different and in a different place depending on the operating system and version you are using. The Apache wiki lists the defaults for most operating systems.
It is important to remember that any changes to the configuration file will not take effect until the service is restarted. As I use the Linux command line, I use the command systemctl restart httpd.service to do this.
Referer Spam
Some people do not know that because it is possible to do something, it isn't always right to do it.
Looking through my web logs realized that the referer links were poisoned and that I was subject to referrer spam which is also known as log spam or referrer bombing. What is supposed to happen is that referer links are supposed to show links to my site from other sites but some people, for some reason mainly Russians, have found they can spoof the referer URL and so add whatever site they like to the web logs.
They do this because many sites, mine included, do not mind who sees those logs. The legitimate search engines index the logs and so the fake referers get their URL added to the search engine results. This is called spamdexing and is one of the techniques of black-hat search engine optimization (SEO).
Some sites say that the web logs are nobody's business except the site owner and so the logs should not be published or at least password protected. I believe in a free and open internet and I am not worried that people can see those logs, in fact, I link to them on some of my pages. Even so, I don't like having my logs poisoned like this and decided to do something about it.
My log file contained thousands of referer links. Part of the log file is illustrated below:
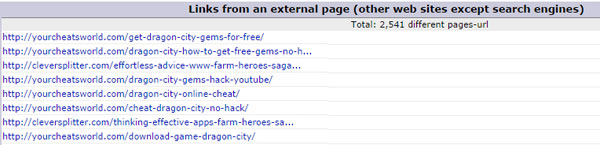
A lot of these sites visited my site hundreds of times in a very short space of time. visiting a couple of them I found that none of them have any links to my pages. I also found some of them were at least a little shady offering things like porn, hacked games and the like. Others seemed more legitimate selling shoes, doors or whatever, other sites were interesting showing artists work and so
on but none had links to my site.
It's a little disconcerting to know that even legitimate looking sites should indulge in black-hat SEO. It could be that the owners really are legitimate but they've decided to go to one of those companies that promise to increase their search engine visibility very quickly and it is those people and companies that have done this.
Using grey- or black-hat SEO can have serious consequences for the companies that use it. The people who run Google, Bing and Yahoo aren't stupid and do not like having their results skewed. companies that do this risk having their rankings in the legitimate search engines reduced or even removed from the search rankings altogether. Fit Marketing has a good article on their site, Fire Your Black Hat SEO Agency! (Internet Archive) explaining why black-hat SEO is not a good idea.
Worse still, because links to these sites are coming from mine, it is conceivable that my site is also being penalized by these search engines.
Semalt is one such crawler that these companies use and these can be identified in the logs by links back to semalt.com, semalt.semault.com or xxxxxx.semalt.com where xxxxxx is any subdomain. Net Security in an article on their site, Semalt botnet hijacked nearly 300k computers (Internet Archive) say that the Semalt bot has been installed as malware on around 290,000 computers as of March 2014.
Short of rejecting all traffic from Russia and Ukraine, where most of this crap is coming from, I thought I'd try a couple of methods of lessening the effect they are having on my logs.
Stopping Individual Sites
The way I decided to stop referer spam on my site was to simply issue a 403 Forbidden message to page requests from these web sites. They do not have a link to my site on the page that accessed my site so I am not losing any real traffic from them.
There are several ways of doing this. One of the most common is by using mod_rewrite as in RewriteCond %{HTTP_REFERER} (semalt\.com) [NC,OR] something similar such as
RewriteEngine On
RewriteCond %{HTTP_REFERER} ^http://(www\.)?spamsite1 *$ [OR]
RewriteCond %{HTTP_REFERER} ^http://(www\.)?spamsite2.com.*$ [NC,OR]
RewriteCond %{HTTP_REFERER} ^http://(www\.)?spamsite3.com.*$ [NC,OR]
RewriteCond %{HTTP_REFERER} ^http://(www\.)?spamsite4.com.*$ [NC]
RewriteRule .* - [F,L]
However RewriteCond is best used where you do not have access to the htppd.conf file and have to rely on .htaccess files. For people with access to httpd.conf then there are usually other, better methods. This is explained in the Apache document When not to use mod_rewrite.
Instead what I did was to set an environment variable.
SetEnvIfNoCase Referer "^http://(www.)?semalt.com" spam_ref=1
SetEnvIfNoCase Referer "^http://(www.)?yourcheats.ru" spam_ref=1
SetEnvIfNoCase Referer "^http://(www.)?yourhackplanet.com" spam_ref=1
A form the command
SetEnvIfNoCase Referer "^http://(www\.)?.*(-|.)?semalt(-|.).*$" spam_ref=1
can be used. This blocks any URL containing the word "semalt".
SetEnvIfNoCase Referer "^http://(www\.)?.*(-|.)?semalt.com(-|.).*$" spam_ref=1
can be used to block semalt.com and any of its subdomains.
Then using the environment variable to block all access to files from these referers by using:
<FilesMatch "(.*)">
Order Allow,Deny
Allow from all
Deny from env=spam_ref
</FilesMatch>
Don't forget, you need to restart the httpd service for changes to httpd.conf to take effect.
Check That It's Working
You need to make sure this is working. You can use a curl command such as:
curl --referer http://yourcheats.ru http://www.brisray.com
or
curl -e http://yourcheats.ru http://www.brisray.com
to check the directives are working. If they are you should see the code for your 403 error page at the command line.
Who They Are
I do not seem to be as affected as some people by referer spammers. If I start to see a pattern in the URLs I'll add a regex expression to block them. I've created a list of the ones who have been poisoning my referer log and this file can be downloaded here.
Problems
A problem with the above method is that I seemed to be playing catchup with these people. As soon as I stop one domain, then several others start spamming the logs. So, my thinking is that if I stop everyone from accessing the logs by password protecting them then it will be a waste of their time and effort spamming me.
There are blacklist files around, the one at Perishable Press for example lists over 8,000 URLS. I would much rather have my server be doing something useful rather than checking thousands of URLs.
Password Protecting the Log Directories
There are plenty of articles around n how to use a .htaccess file to password protect directories but as I run my own server I have access to httpd.conf and so used that.
A .htpasswd file can be created by using:
htpasswd -c /path/.htpasswd username
A prompt appears to supply a password for the username. The form of the command I used was:
htpasswd -c /etc/httpd/conf/.htpasswd brisray
The -c in the above commands is to create the .htpasswd file. If further username and password pairs need to be added, it should be omitted otherwise the original file will be overwritten.
The permissions on the file have to be altered so the following command is used:
chmod 644 /etc/httpd/conf/.htpasswd
Next, the httpd.conf file has to be amended to show which directory needs to be protected, who the authorized users are and where to find the .htpasswd file that contains the passwords. I used:
<Directory /var/www/html/brisray/utils/alogs>
AllowOverride AuthConfig
AuthName "Use brisray for both"
AuthType Basic
AuthUserFile /etc/httpd/conf/.htpasswd
AuthGroupFile /dev/null
require user brisray
</Directory>
Real visitors to the page will see the instructions to access them, "Use brisray for both" but the bots and spiders won't be able to.
The official Apache documentation is at Authentication
and Authorization.
robots.txt
Stopping Well-Behaved Bots and Spiders from trying to Index the Log Directories
Robots.txt is in the root of my web site and it tells well-behaved bots and spiders what directories they can crawl and which they cannot. Although nothing should be access the log directories now they are password protected I decided to disallow them in robots.txt as well.
My thinking behind this methods and the one about password protecting the log directories is that the whole point of referer spamming is to get the sites that do it referenced in the legitimate search engines such as Google, Bing and Yahoo.
If the log results do not appear in the search engine results there's not much point in poisoning my logs. The problem is that the pages have already been indexed, and it's going to take a while before those are removed from the search results.
The entry in robots.txt looks like this
User-agent: *
Disallow: /utils/alogs/
Disallow: /utils/wlogs/
to be sure that the bots do not crawl, index and follow links in these blocked pages is to use:
<meta name="robots" content="noindex,nofollow">
in the head section of every page that is not to be crawled. I do not need this as the entire directory is now password protected as well.
It should be remembered why this is. The well-behaved bots will not directly crawl the directories disallowed in robots.txt but they will follow links to files in the directory if it appears on other pages. This is why the meta name="robots" tag is required. also, the bots may not crawl the directory but they could list it in the search engines as a URL with no content.
Also, there is not reason why a badly behaved bot or spider will not read the robots.txt file or ignore it altogether and crawl the disallowed directories and
files anyway.
This page created September 28, 2014; last modified August 8, 2021